
It’s Now in the Documentation
The Art and Business of Photography in the Era of AI Free Issue

In May I wrote about Danny Sullivan’s talk at Google Search Central Live in Toronto, where he laid out the case for non-commodity content in plain terms: commodity is finished, the path forward requires perspective and firsthand experience, the test is whether only you could have written it. That was an official Google voice making an argument in public.
On June 5th, the argument landed in Google’s formal developer documentation. Not one page. Three, coordinated. That’s a different kind of signal.
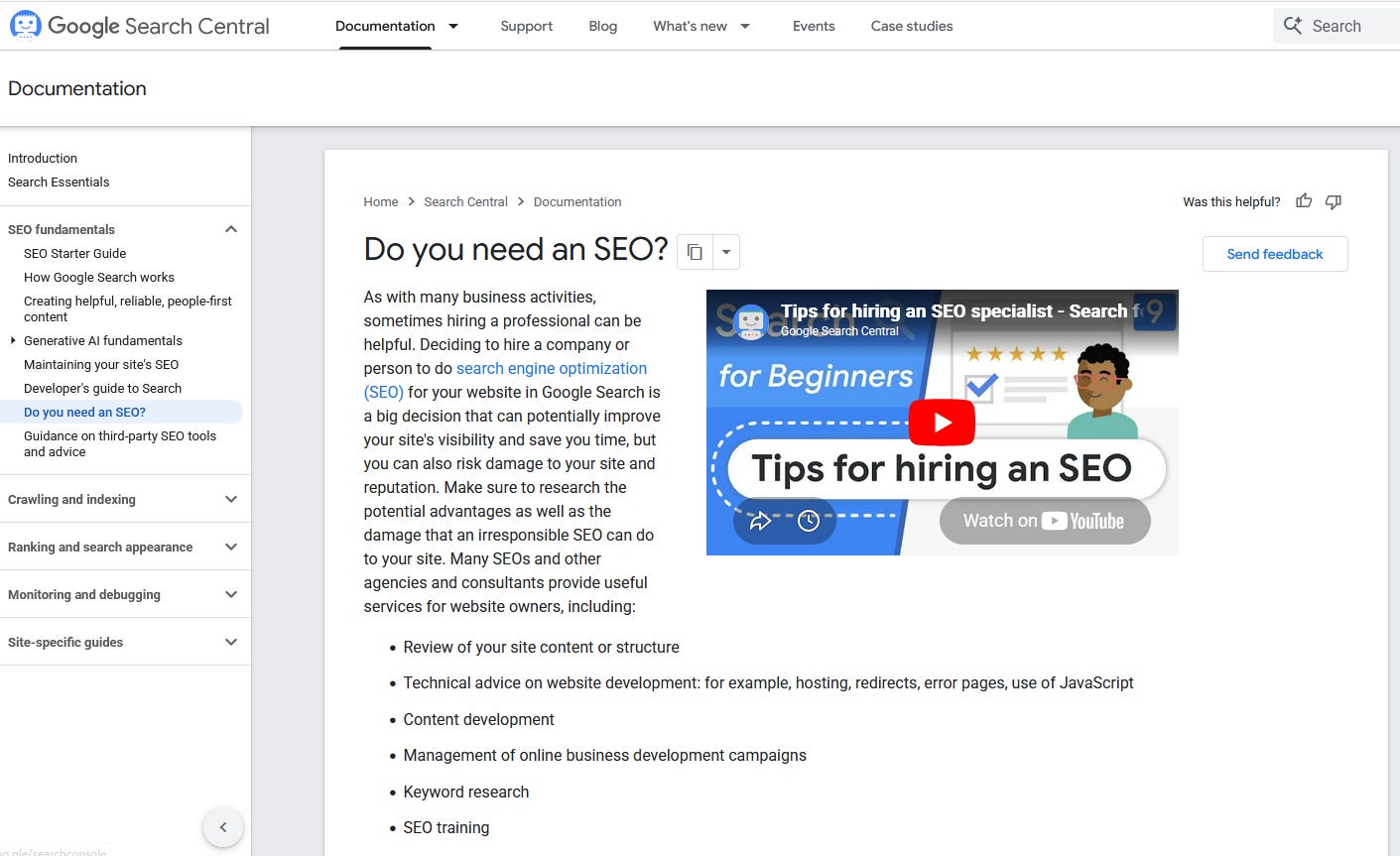
The first is the “Do You Need an SEO?” guidance page, which lists the services worth paying a professional for. The updated list now ends with this: “Optimizing for generative AI.” Lower on the same page, in a new section on evaluating an SEO’s tools, Google names the discipline directly: “advice on optimizing for AI experiences (also known as ‘AEO’ ‘GEO’ services).”
Not a conference talk. Not a blog post from a marketing agency. Google’s official hiring guidance.
The second is a new page dedicated to evaluating third-party SEO tools and advice. It covers the range of services claiming to help with AI search visibility, and on the tooling specifically, it says: “Third-party tools don’t have access to our internal ranking data. They can’t guarantee performance. Any predictions are their own and like predictions generally, may not happen.”
The third is the one that completes the move: a dedicated official guide on optimizing for generative AI features, which both of the other pages now link to. So the picture as of June 5th is three coordinated parts. The service is worth paying for. Here is how to evaluate the tools claiming to do it. Here is our own guidance on how to do it.
Read together, the updates make the same argument Sullivan made in Toronto, but now it’s in the documentation: AEO is real enough to pay for, and the tooling claiming to measure it is unreliable enough to scrutinize carefully.
I’ve been sitting with that second point for a while.
After the May issue I started running my own brands through the HubSpot AEO Grader, which is the tool Kipp Bodnar used for his live demo in the Marketing Against the Grain episode I referenced. The grader produces scores across multiple dimensions: brand recognition, share of voice, presence quality, sentiment. It generates competitor comparisons.
It has problems. I found them. And then I built something else. It’s not pretty, but it is effective.
The next two issues cover what I found and what I built. They’re specific, they’re mine, and they’re behind the paywall, which is where the methodology work in this newsletter lives.
The arc over the next three weeks:
Issue 2 (June 17, paid): What the tool found on a mature photography brand.
I ran seven subspecialty queries against Michael Kloth Photography, the business I’ve operated since 2006, with 20 years of credentials, two published books, and a Wikidata entity. The signal web behind it is real: PPA, ASMP, the TMC Foundation collection, Getty Images.
The scores ranged from 28 to 78 depending on the AI provider and the subspecialty. That spread isn’t a calibration error. It’s structural, and understanding why Grok and Perplexity score the same brand 50 points apart on the same query is the first thing you have to understand before any of this is actionable.
Issue 3 (June 24, paid): What the tool found on a three-month-old newsletter brand, and why I stopped using the HubSpot grader.
I also ran the tool on artofphotographyai.com, this newsletter, three months old, scoring in the 40s across the board. A newer brand has a cleaner failure profile. The gaps are diagnosable and the remediation path is explicit.
That issue also covers the HubSpot grader’s architecture problem, what I found when I looked inside it, and why a client acquisition funnel dressed as a diagnostic tool produces a specific kind of unreliable output that Google’s June 5th documentation is, whether intentionally or not, describing exactly.
The May issue ended with this: the strategy question isn’t whether to build non-commodity content. It’s recognizing which decisions have been optimizing for the wrong thing.
The June documentation adds a layer: the measurement question isn’t whether to evaluate your AI visibility. It’s recognizing which tools are built to answer your question versus which ones are built to answer a different question entirely, and produce your score as a byproduct.
Both problems have the same shape. That’s not a coincidence.
Issues 2 and 3 are for paid subscribers. If you’ve been reading this newsletter on the free tier and the direction this is going sounds useful, this is a reasonable moment to consider upgrading.