
Google Just Said the Quiet Part Out Loud
What the new non-commodity content framework means for photographers, and what happens when you run it against a real site

Last week, Danny Sullivan spoke at Google’s Search Central event in Toronto and said something photographers need to hear. The short version: commodity content is finished. The path forward requires perspective, expertise, firsthand experience, or a voice that only you can provide.
This isn’t a new idea. It’s a newly official one.
Sullivan’s framing at the event was commodity versus non-commodity content. Commodity content is factual, widely available, offers no unique perspective, and requires no expertise to produce. Non-commodity content carries your original voice, your particular take, your firsthand experience. The test he offered: only you could have written it.
Kipp Bodnar at HubSpot picked up the framework almost immediately in a Marketing Against the Grain episode, extending it into a six-checkpoint version with a grader tool. That’s where I encountered it, and it’s what I’ll use for the audit below.
If that framing sounds familiar, it should. This newsletter has been calling the same thing the generic photographer problem since March. The argument I’ve been making is that AI tools without voice infrastructure produce output indistinguishable from what any model would generate for any photographer anywhere. Sullivan is making the same argument from the search side. The language is different. The problem is identical.
I find it useful when Google confirms something I’ve been worried about for a while. Less useful when I realize I need to go audit my own site.
The framework
He built a grader around the six checkpoints that scored the top-ranking Google result for countertop material comparisons at 9 out of 100 during a live demo in the episode. A page sitting at number one on Google, scored against this framework, nearly bottom of the scale.
That’s the gap between traditional SEO ranking and AI-era discoverability in one number.
The six checkpoints:
Proprietary evidence. Data or documentation only you could have. Not “professional photographers recommend” but a specific customer’s shoes at 402 miles with 4mm of foam compression on the right heel, photographed in your shop.
First-hand experience. I did, I saw, I built. The word “I” followed by a verb describing something that actually happened.
Specificity. Names, numbers, dates, places. The test Bodnar offers: for every adjective, ask whether you could replace it with a number, name, or date. Fast becomes 11 seconds. Popular becomes 4,200 orders last month. Recent becomes March 14th.
Point of view. A line you’re willing to lose business over. The example from the episode is a countertop installer who won’t put marble in a house with kids, and will walk away from the job. The test: can you start a sentence with “I believe” or “I won’t”? If not, you don’t have a point of view, you have a position statement.
LLM test. Could ChatGPT write this without your input? If yes, it’s commodity. If the piece depends on your being there, on something you documented, on something only you could have observed or decided, it passes.
Information gain. Does the reader learn something not in the top three Google results? Before publishing, search your own headline and read what comes up. If you can’t circle three facts in your piece that aren’t already out there, your information gain is zero.
What happens when you run it against a real site
I ran it against michaelklothphotography.com using Bodnar’s grader, because if I’m going to argue that photographers need to think about this, I should be willing to show what it looks like on my own pages.
The first result stopped me. I submitted the blog URL and got a score of 21 out of 100. Mostly commodity. The grader’s verdict: “Teaser-only excerpt with a compelling hook but zero payoff — no data, no visuals, no firsthand detail delivered.”
Which is accurate. The blog index page surfaces teasers, not full posts. The grader evaluated what it could access, which was a premise and a “Read More” button. That’s not a failing grade on the blog. It’s a correct evaluation of what a blog index page actually is — and a useful illustration of how algorithms encounter your content when they can’t get past the surface.
I ran two actual posts next.
The parking lot/OR post — a session at Friends of PACC that started with a dog escaping in the parking lot and ended in a veterinary surgical suite — scored 69. The grader’s summary: “Strong firsthand storytelling with specific clinical detail, but undersells its own proprietary evidence.” Its evidence for the non-commodity rating: the runaway dog, the disconnected power adapter, the Valley fever radiograph series. Details, it noted, that no LLM or generic photography blog could fabricate. The score is held back by missing images in the text and a few passages that slip into explanatory mode.
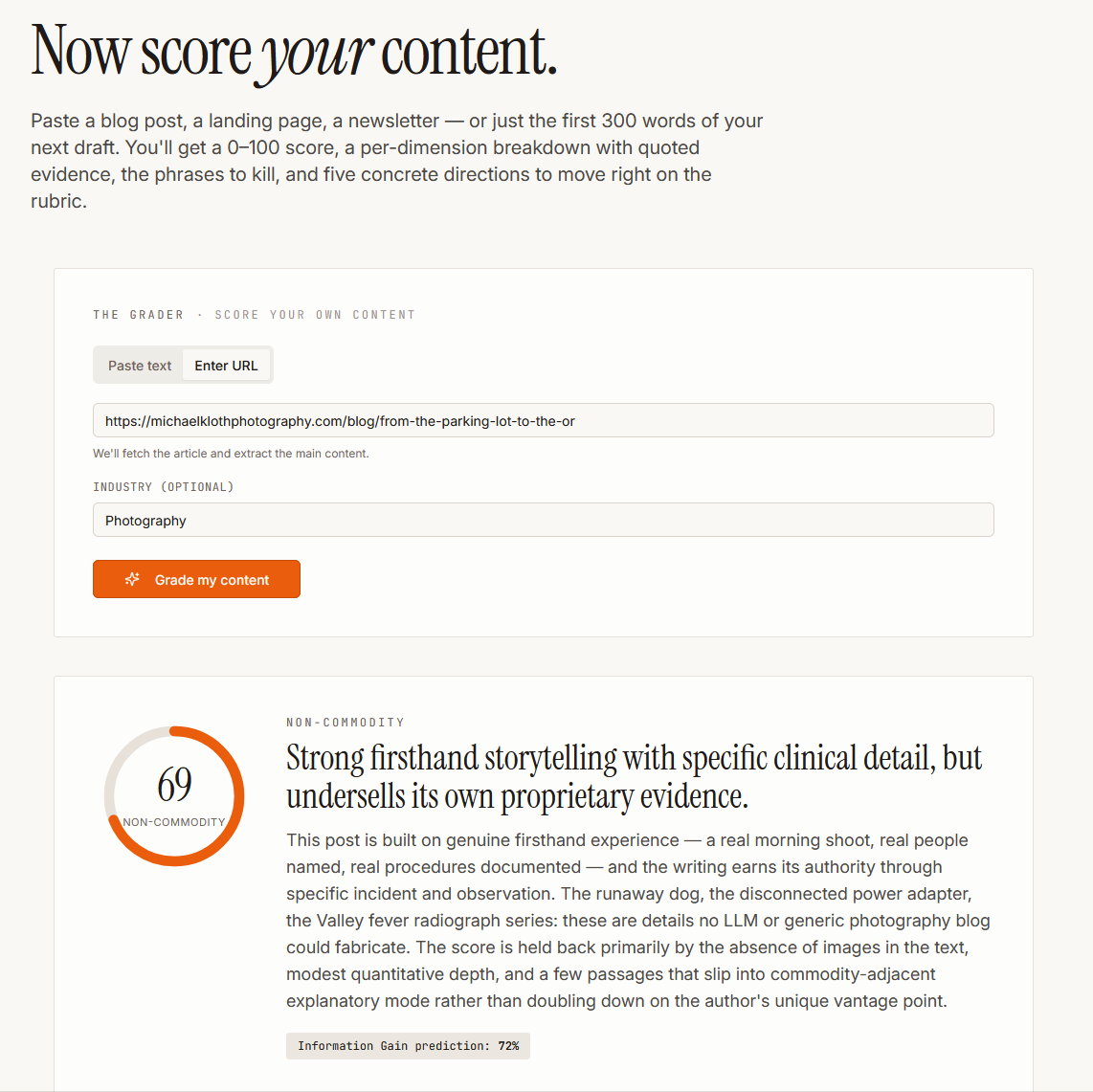
Even Odds, the shelter photography retrospective published in March, scored 74. The grader’s headline: “Twenty years of dated metadata, grant-impact footage, and euthanasia statistics the author personally witnessed make this genuinely non-commodity.” It correctly identified the grant-impact footage and the direct causal link between the photography and a funded behavior program as the load-bearing elements. Points lost for passages that drift into reflective generality rather than scene-level specificity.
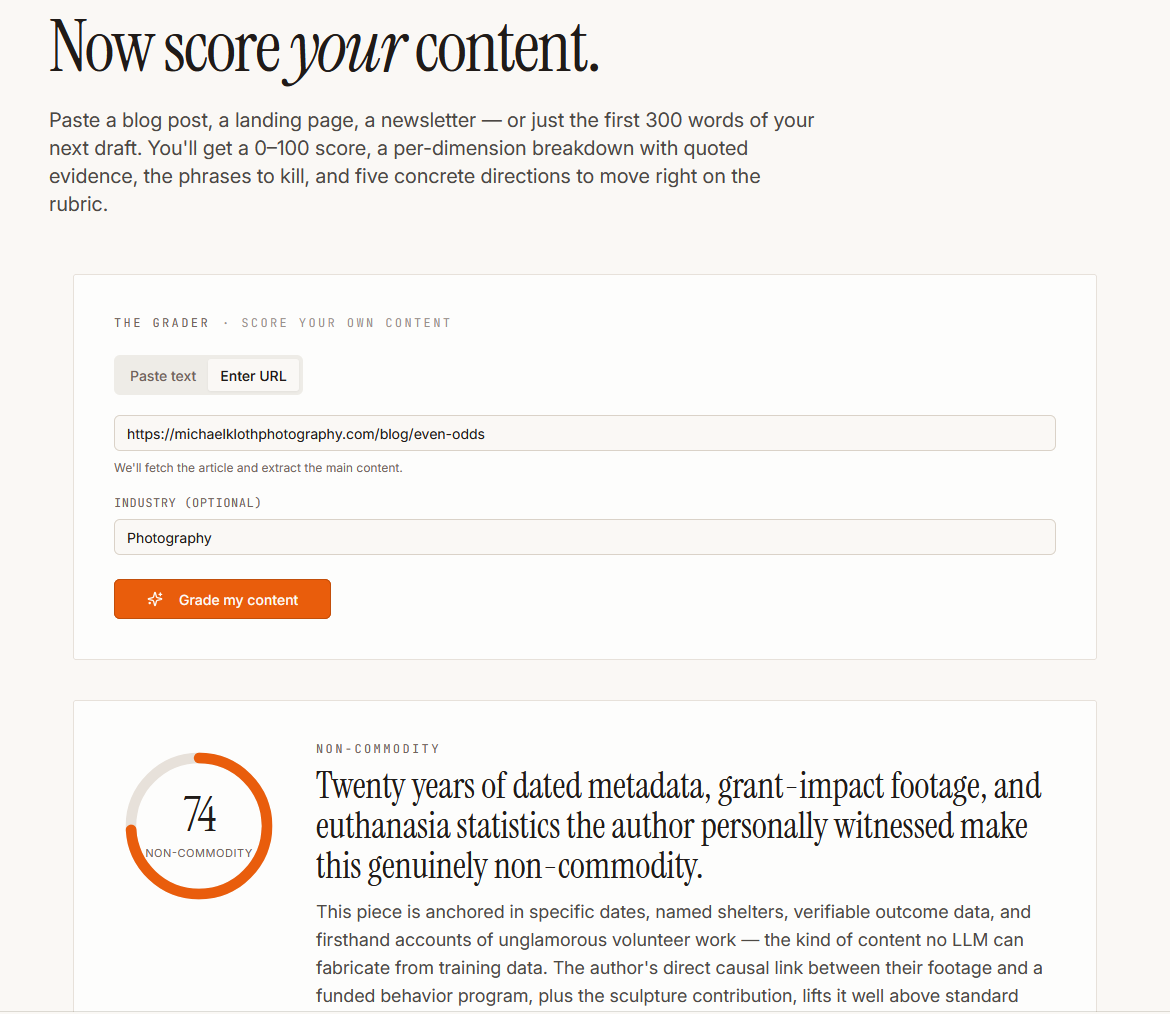
Three scores: 21, 69, 74. The 21 is a grader limitation — it evaluated a teaser, not a post. The 69 and 74 have a limitation of their own worth understanding: the grader couldn’t read the images. Squarespace serves images through its CDN with captions as separate elements, and the grader treated them as absent from the content. Both posts have images with captions. The grader scored neither of them. The 69 and 74 were earned on text alone. The actual posts are stronger than the scores reflect.
That’s the finding worth sitting with: the content doing non-commodity work scored in the non-commodity range without the grader being able to see roughly half its evidence.
The first thing the audit clarified is that the framework doesn’t apply uniformly across a site. Service pages and blog posts are solving different problems, and conflating them produces a misleading result. That doesn’t mean there isn’t something to learn though.
A service page is navigational and transactional. Someone searching “Tucson headshot photographer” is trying to answer three questions: do you do the thing I need, what does it cost, and how do I book you. That’s a commodity search intent, and the right answer to it is a page that’s clear, credentialed, and easy to navigate. Weaving in non-commodity storytelling where someone is trying to check a box is friction, not value. The service pages on the site are doing exactly what service pages should do.


The framework applies where someone is researching rather than ready to book. Blog posts. Informational queries. “How much do professional photos of a dog cost.” “Do headshots matter for LinkedIn.” That’s where the non-commodity requirement is real and consequential, because that’s where Google and LLMs are deciding whether your site demonstrates actual expertise or just answers the question adequately.
So the audit finding isn’t “the service pages fail the framework.” It’s that the framework applies differently depending on what a page is trying to do, and the blog is where it matters most.
What the blog is doing right.
The “Even Odds” post has the specifics the framework calls for: the 2015 training pilot, the 14,000 fewer euthanasias figure, the rainstorm session where what the shelter actually needed wasn’t photography. First-hand experience documented at the level Sullivan is describing.
The dog photography pricing post passes the information gain test because it’s honest market data from someone who’s worked with thousands of dogs, positioned to help readers decide whether to book me or someone else. That’s a perspective no aggregator site can replicate.
The Friends of PACC post — the one that scored 69 — wasn’t written with this framework in mind. It was written because the session happened and was worth documenting. The score reflects that. When the underlying experience is real and documented at the right level of specificity, the framework takes care of itself.
Where the gap actually is.
The commodity content on the site didn’t happen because the writing got lazy. It happened because some posts were written to answer search queries rather than to document experience. That’s a structural decision, not a writing failure. “Do headshots matter on LinkedIn” has search volume. “What I learned photographing anxious lawyers” does not. Most photographers make the same call.
The dentist who writes “How to Choose a Dentist in Atlanta” gets buried in AI Overviews. The dentist who writes “Why I Refused to Place an Implant on This 67-Year-Old Smoker” gets cited. The search-volume version of the headshot post answers the question adequately. The experience-documented version is the one that only I could have written.
That’s the tension the framework surfaces. Not a writing problem. A strategy problem. And the corrective isn’t to rewrite every informational post — it’s to understand which content is earning discovery and which is just answering the question everyone else is also answering.
The distinction the framework keeps returning to
Bodnar’s test for point of view is worth sitting with: can you start a sentence with “I believe” or “I won’t”?
The countertop installer says: I won’t put marble in a house with kids. I’ve done too many etched surfaces for families who wanted the look. Quartzite or nothing.
What’s the photography equivalent?
I have positions. I don’t deliver same-day digital galleries because I’ve seen what rushed editing does to a portrait, and I’m not willing to put my name on work that hasn’t had time to breathe. I won’t retouch out features that define someone’s face. I’ve walked away from conversations where what the client wanted and what the portraits needed were too far apart to close.
Those positions exist. Most of them aren’t on the site yet.
That’s the gap the framework identifies, and it’s useful because it’s specific. It’s not “be more authentic” or “show your personality.” It’s: name the line, state it plainly, accept that some readers will disagree with it.
Why this matters more now than it did six months ago
Sullivan’s observation at the Toronto event is worth taking seriously: AI features speed up a reality publishers have already been facing for years. Commodity content was always replaceable. What’s changed is the speed of replacement and the scale of the competition.
A blog post that could have been written by any photographer, about any market, for any reader, competes with every other post written the same way. In an LLM’s training data, those posts blur together. In an AI Overview, the one that gets cited is the one that contains something the others don’t.
The photographers building non-commodity content now aren’t doing something exotic. They’re documenting what they actually do, with the specificity of people who were actually there, from a point of view they’re actually willing to defend. The strategy question isn’t whether to do this. It’s recognizing which content decisions have been optimizing for search volume when they should have been optimizing for irreplaceability.
That’s the work. The framework just makes it easier to see where it’s missing.
The connection between this framework and the persistent identity methodology I write about in the paid tier is direct: what Sullivan is describing from the search side is the same problem the generic photographer concept describes from the AI output side. The mechanism underneath both is the same. The conversation will continue to evolve.